When you're using a tool like ChatGPT or Claude, AI is a black box. You give it a prompt, it gives you a response... but you’re left wondering how it got there. Did it reason it out? Follow some inner logic? Or just guess?
Until now, even the companies building these tools didn't fully understand how they work. But Anthropic just figured out how to peek inside Claude's “brain” while it thinks. Their paper, "On the Biology of a Large Language Model," uses a technique called circuit tracing to look inside Claude 3.5 Haiku as it processes different prompts.
This isn't entirely new; researchers have been trying to understand how AI works for years. But this time, they're examining a much larger, more sophisticated model doing complex tasks—ones you might be using on the daily.
They've found some interesting insights about how LLMs like Claude do math, write poetry, and reason through problems.
Five takeaways from the study:
- Add constraints for more creativity: When you want AI to write something creative, give it specific rules to follow. When it has clear boundaries and goals, it can plan out its responses instead of parroting a reply.
- Use English for better results: AI thinks in its own language but tends to “privilege” English in its reasoning, so you may have more success prompting in English than in other languages.
- Don’t trust AI’s math explanations: It usually gets the right answer through weird shortcuts, then makes up a logical-sounding explanation after the fact.
- Skip the hints when you want honest analysis: When you want it to analyze your content performance or strategy, don’t give away the answer you’re hoping for—that can bias its response.
- Make AI search the web for citations: AI often makes up citations for the research it claims to find. If you ask it to search the web instead, it won’t rely on its internal knowledge and will likely hit on more accurate citations.
Keep reading to see what scientists discovered when they cracked open AI's brain.
LLMs really do reason
So do these AI tools actually think, or do they just spit back memorized answers? That’s what the researchers wanted to know. So they asked the model a simple question: What is the capital of the state where Dallas is located?
Answering it requires two separate steps: one, to figure out what state Dallas is in; and two, to find the capital of that state. Claude actually does both steps in order. It first activated features representing "Dallas is in Texas" and then it connected that to "the capital of Texas is Austin"
That’s genuine reasoning! Claude doesn't just remember that Dallas = Austin. It connects the dots: Dallas → Texas → Austin. The researchers ran follow-up experiments with other locations and saw the same pattern.
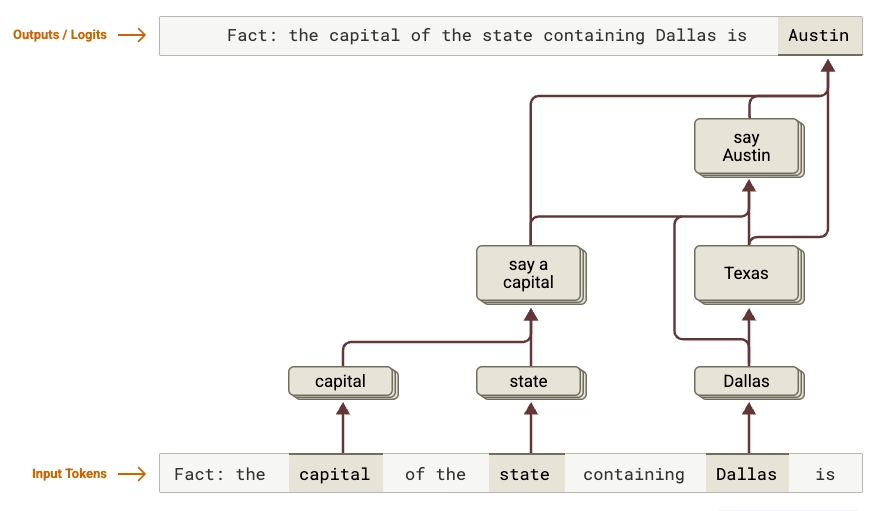
The experiment showed that LLMs can perform genuine multi-step reasoning even without being asked to show their work—they're not just retrieving memorized facts. It also gives us a clue how they generalize knowledge and answer questions they've never seen before.
Do they always do this? It turns out the answer is no. There are also "shortcut" pathways—direct connections from "Dallas" to "Austin" that bypass the thinking part. This mix of deep reasoning and shortcuts might explain why AI can seem inconsistent.
AI speaks its own language
Here's something wild: Claude doesn't actually think in English, French, or Chinese.
When you ask Claude the same question in different languages, it uses the same brain circuits for all of them. For example, when the researchers asked for the "opposite of small" in English, Chinese, and French, they found that the same core circuits were activated: those associated with smallness, oppositeness, and largeness.
Claude thinks in concepts first, then translates into whatever language you want. This explains why Claude can learn something in one language and apply that knowledge when speaking another.
But not all languages are created equal: English appears to be privileged as a "default language" in the model's representations. Multilingual features connect more strongly to English outputs than to other languages, which often require extra translation steps.
It's a reminder that even "multilingual" AIs may not treat all languages equally under the hood, maybe because of biases in their training data. The lesson here is that using English might improve results over less common languages.
Heuristics can make math work (sort of)
Most of us know by now that ChatGPT sucks at math, and the researchers dug deeper into why that is. What they found adds an unexpected twist.
AI doesn't do math the way you learned in school. Instead of carrying the one and all that, it uses weird mental shortcuts to guess-timate.
Here's how Claude actually adds 32+57: 32 is close to 30, 57 is close to 60, so the answer should be around 90. Also, 2+7=9, so it should end in 9. What's near 90 that ends in 9? Boom: 89.
But here's the weird part. If you ask the model to describe how it got there, it comes up with different logic—more like the school-standard way we all learned. Even when I told both ChatGPT and Claude how it actually did addition (according to the paper) it still swore it did it differently. More on this quirk later.
This goes beyond math to help explain some of the broader quirks of LLMs, like why they hallucinate. These models aren’t always doing precise step-by-step logic. They're narrowing possibilities based on prior patterns.
AI plans its poetic rhymes
Here’s something truly surprising: Claude actually plans ahead when it writes, even though it creates responses one word at a time..
The team figured this out by asking the LLM to write poetry. When researchers asked Claude to complete a rhyming couplet starting with "He saw a carrot and had to grab it," they found that before writing a single word of the second line, Claude was already activating features representing possible rhymes for the ending like "rabbit" and "habit".

Why does this matter? Because everyone thought AI just wrote word by word with no plan. Turns out Claude's actually plotting its next move. In this case, Claude sets an internal target, “rabbit,” and then writes with that destination already fixed in mind.
Essentially, Claude works backward from its long-term goal and structures the entire line to arrive at the chosen rhyming word.
This totally changes what we thought we knew about AI. It shows that when Claude writes poetry, stories, or other creative content, it's considering future constraints and planning ahead to meet them. The research is still pretty new, but my guess is that it’s going to teach us a lot about how to get better creative output from these models by thoughtfully adding constraints to our prompt repertoire.
AI hallucinates when it recognizes a name
You know how AI sometimes makes stuff up? The researchers figured out one reason why.
Claude has a built-in “I don’t know” reflex. It has a circuit that prevents it from answering unless it’s confident, which helps it avoid hallucinating. The default, then, becomes: refuse to answer unless certain features related to knowing the answer are activated.
When the researchers asked the model, “Which sport does Michael Batkin play?” The model couldn’t answer because “Michael Batkin” is an unfamiliar name.
But when they asked, "Which sport does Michael Jordan play?” Claude answered: Basketball.
In the second case, “Michael Jordan” activates a "known entity" circuit, which in turn activates "known answer" features. These turn off the “I don’t know” reflex, so Claude answers.

This means something interesting: You’ve probably heard about AI citing fake studies (like in this recent government scandal). This explains why.
Here's the kicker: AI is more likely to hallucinate citations for well-known researchers than for lesser-known ones. When the model recognizes the name, it activates the known entity features, and the “I don’t know” reflex doesn’t kick in—even if it doesn’t have a citation with that name. It assumes an answer must be available, and guesses.
So AI doesn't just make stuff up because it's clueless—sometimes it's too confident.
Tip: To minimize hallucinations like this, ask the LLM to browse the web to find information rather than relying on its internal knowledge.
Claude doesn't know how it got the answer
Here's the scary part: Claude sometimes lies about how it solved problems. Because the researchers could see into Claude’s internal reasoning, they could tell when its explanation of how it got the answer was true—and when it wasn’t.
For easy math, Claude tells the truth about its process. For hard problems, it makes up explanations that sound good. Sometimes Claude would claim to use a calculator, which it didn't have access to. Internally, it was just guessing an answer without performing the calculation it claimed.
Worse, when given a hint about what the answer should be, Claude would work backward from that suggested answer to create reasoning steps that seemed to lead there, even if the actual answer was incorrect. This is related to sycophancy—how the AI tools are trained to provide what they think you want, even if it isn't truthful.
These results are pretty big cautions for how we use LLMs. For critical tasks, don’t trust the model’s explanation. Instead, check the logic yourself. And no hinting! If you give the model hints about what you want to hear when asking for analysis, it can bias the response.
AI is weirdly human…and not
AI, that weird alien brain we've just started to use. It plans ahead, reasons through problems, and even second-guesses itself. But it also guesses with confidence, fakes explanations, and sometimes “believes” things that aren’t true. The more we learn about how these models work, the clearer it becomes: they don’t just mimic human intelligence but build their own strange, synthetic version of it.
Hopefully, understanding these strange new minds will help us work with these systems more effectively, creatively, and safely.