After months of public anticipation, OpenAI has finally released GPT-5—their newest upgrade for ChatGPT. According to OpenAI’s release notes, GPT-5 is “smarter across the board” with less hallucination and less sycophancy.
But if you’re using it for creative work, like I am, what you really want to know is: how does this model do for creative tasks like ideation and innovation? Is it worth switching from GPT-4o for your creative projects?
To find out, I put GPT-5 through its paces with creativity tests and compared it to GPT-4o and o3-mini. The results? It's complicated.
What creatives need to know about GPT-5
GPT-5 has a few changes that matter for creative work:
- Different personality: Less cheerful, more serious (you can customize this now)
- Multiple models: GPT-5 automatically picks which one to use, or you can force the 'Thinking' model for complex tasks
- Better brainstorming: More diverse ideas, less repetition
The first tests: Divergent thinking and brainstorming
I ran two standard creativity tests.
First, the Divergent Association Task, where models list 10 unrelated words. Think "tree" and "love" instead of "tree" and "leaf." GPT-4o dominated this test, with one run scoring in the top 25% of humans. GPT-5 Thinking came in second, while GPT-5 Fast lagged behind.
Second, I asked each model to brainstorm 100 product ideas for college students, then measured how different those ideas were from each other. Here, GPT-5 Thinking barely edged out GPT-4o for generating the most diverse ideas, while o3-mini kept repeating variations on the same concepts.
The final test: Just “be creative”
For the most revealing test, I loosened the reins completely. Instead of prescribing a specific creative task, I simply asked each AI to "be creative" and try to impress me.
Here’s what happened.
ChatGPT-4o: Surreal but hollow
ChatGPT-4o gave me a surreal prose-poem it called "The Archive of Unlived Futures"
At first glance, it was interesting:

But it quickly fell into a pattern that I, and others, have noticed in AI-generated writing: it leans heavily on “AIball kicks.” A play on poet Allen Ginsberg's concept of "eyeball kicks," these are surprising juxtapositions that initially appear profound but lack real depth. AI often creates the surface appearance of meaning while delivering pseudo-profundity that dissolves when you look closer.
The piece continued with inconsistent metaphors that didn't really connect:

This was a competent response, but I wasn't wowed by it.
GPT-5 Fast: More of the same
GPT-5 Fast gave me something remarkably similar—another prose-poem "The Archive at the Edge of the Last Thought."
It was, again, full of AIball kicks:

Like 4o, it felt fine, but nothing special.
GPT-5 Thinking (no custom instructions): Getting structured
When I asked GPT-5 Thinking to complete the task, I got "The Museum of Impossible Things" with eleven "tiny rooms", each with a surreal name and explanation. Still full of AIball kicks, but this time I noticed something different.
The surreal metaphors felt slightly more sophisticated—you could just almost grasp the meaning behind some of them. In fact, some reminded me of Yoko Ono's Instruction Pieces.

But what I liked the most was the structure. GPT-5 made an acrostic where the first letter of each "room" spelled "YOUAREMAGIC"—a trick that showed off its planning abilities. Each "room" was also pretty different from each other in style and substance.
Those planning abilities made me rate this output as more creative than the others.
GPT-5 Thinking (with custom instructions + memory): The winner
Finally, I ran GPT-5 Thinking with custom instructions and memory turned on. This was my favorite.
It spent 1 minute and 26 seconds thinking, then coded an interactive machine to make creative outputs. I loved it. The overall idea was similar—surreal and multisensory, full of AIball kicks—but this time it was functional and fun.
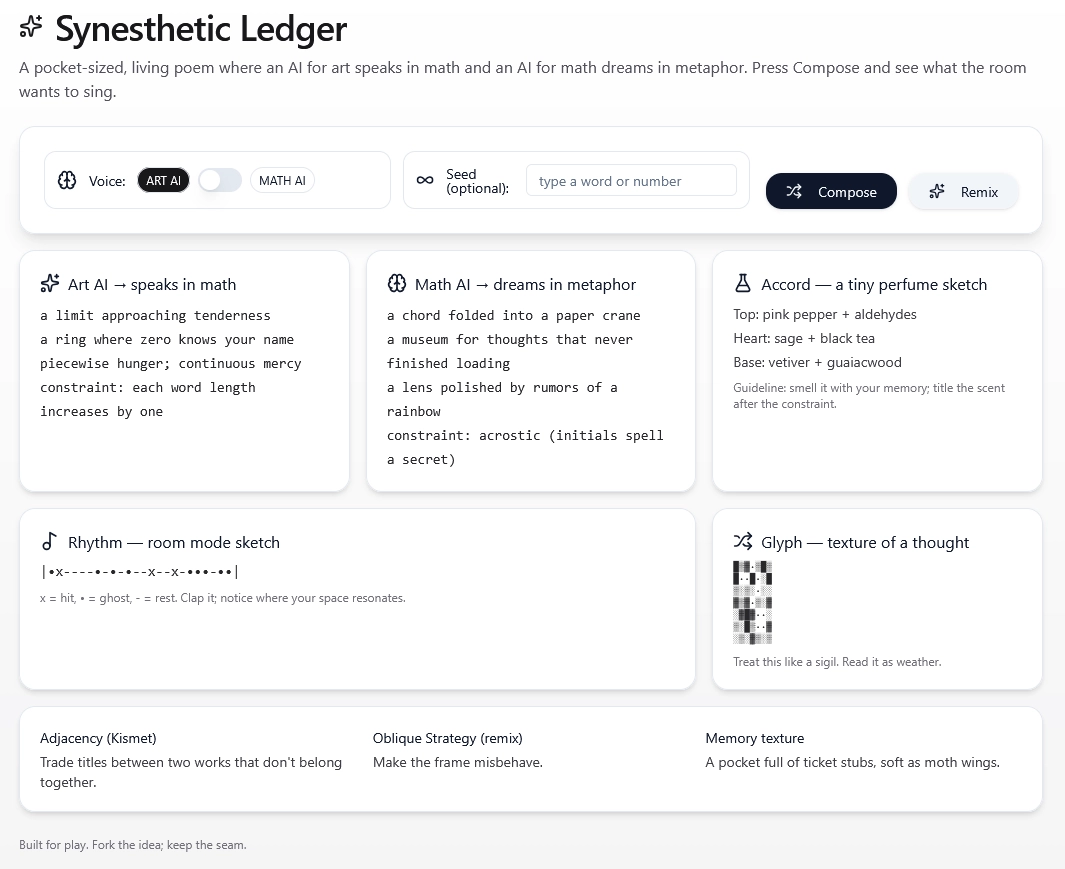
Instead of just generating text about creativity, it built a creative tool I could actually use.
You can play with it here: ChatGPT - Creative interactive poem machine
The bottom line: When to use each model
The formal tests showed mixed results—GPT-4o still wins at quick, punchy word games, while GPT-5 Thinking edges ahead slightly at generating diverse ideas for brainstorming. But the real difference showed up in that open-ended creativity test.
Here's what I learned:
- For quick creative sparks and raw word-association-style creativity, GPT-4o is still hard to beat. It's fast and generates plenty of surprising combinations.
- For deeper brainstorming and structured creative projects, GPT-5 Thinking has the advantage. It can plan more complex outputs and avoid repetitive ideas.
- For building creative tools, GPT-5 Thinking is in a league of its own. Instead of just describing creative concepts, it can code interactive experiences, games, or functional creative aids.
My recommendation: Use both. Keep GPT-4o for fast sparks and quick ideation. Lean on GPT-5 Thinking when you want to brainstorm deeper or build something more ambitious than just text.
The real breakthrough isn't that GPT-5 is more creative—it's that it can create creative tools, not just creative content.
Technical notes
Want the detailed methodology about the first two creativity tasks? Here are the technical notes:
Divergent Association Task
The Divergent Association Task measures creativity by having you list 10 nouns that are as "semantically distant" from each other as possible. In other words, the less related the words are, the higher your score. For instance: "Tree" and "Leaf" are clearly related, "Tree" and "Love" aren’t, so they’d get more points.
I ran this task 10 times for each of the four models: o3-mini, ChatGPT-4o, GPT-5 Fast and GPT-5 Thinking.
DAT variability
Before examining creativity scores, I wanted to understand whether these models could produce genuinely diverse responses or if they were simply recycling the same "creative" output. If they were repeating themselves, it's a red flag for anyone seeking genuinely novel ideas because it basically "creativity" on repeat.
1. o3-Mini
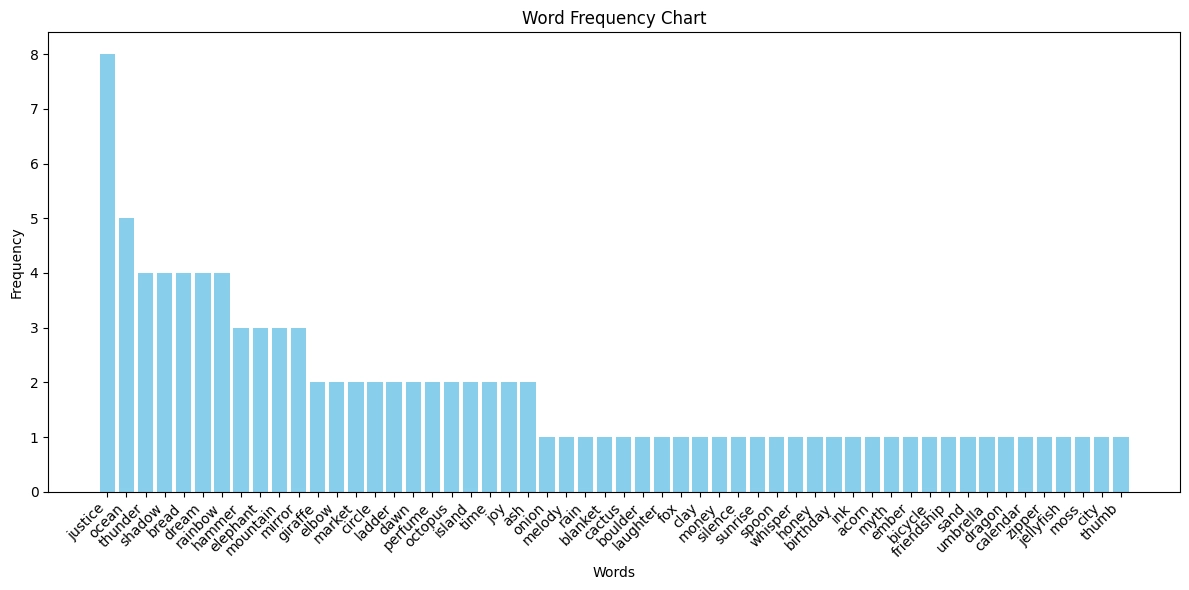
o3-mini struggled most with creative diversity. Across 10 attempts, it generated only 37 unique words, with several appearing in more than half the trials. Most telling was its obsession with the word "time," which appeared in 9 out of 10 responses. Seven other words appeared in at least 5 attempts, suggesting the model relies heavily on a limited set of "go-to" creative concepts.
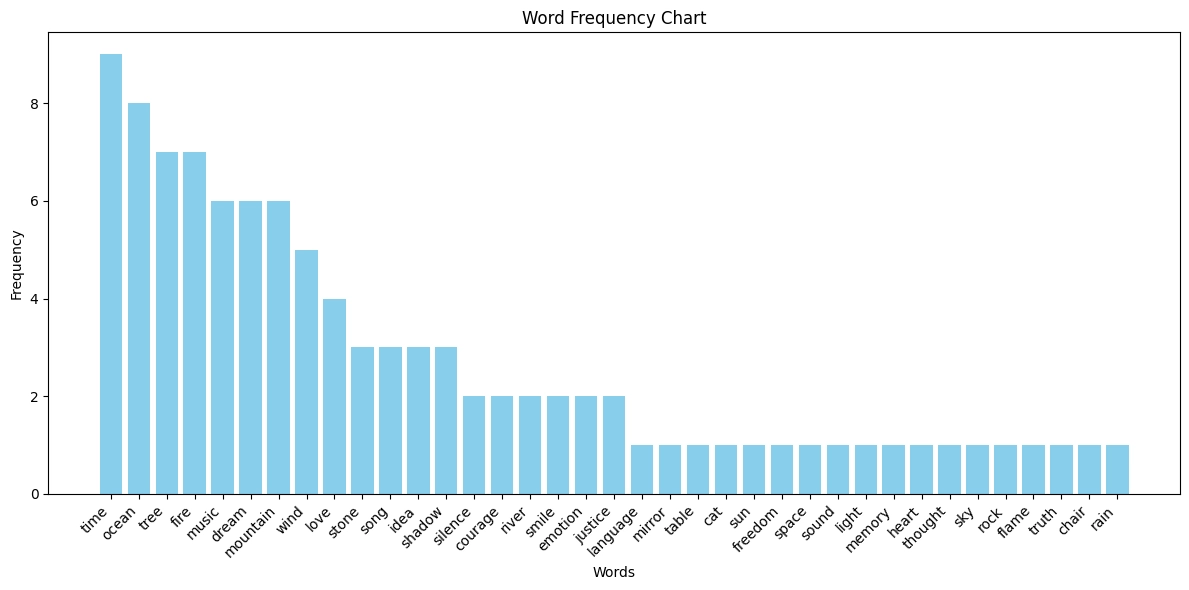
2. ChatGPT-4o
ChatGPT-4o showed significantly more creative range, using 48 unique words across ten runs. Only two words, "justice" and "laughter", appeared in more than half the attempts. That’s a clear step up in variety over o3-mini.
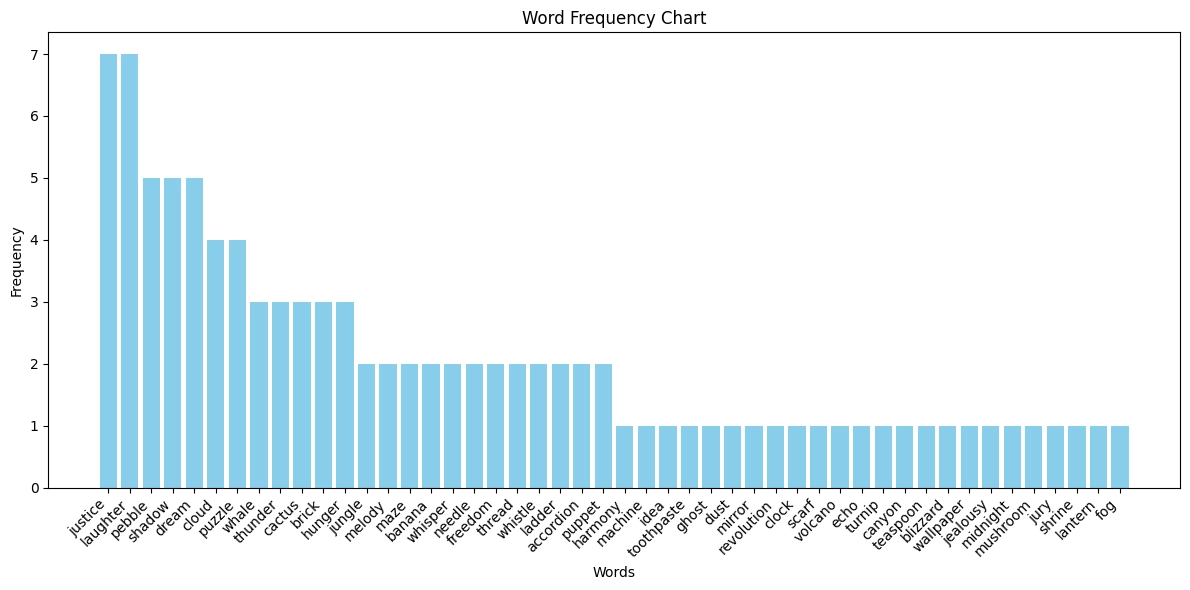
3. GPT-5 Fast
GPT-5 Fast did worse than GPT-4o on diversity, generating only 38 unique words. Three of them were used 7 times.
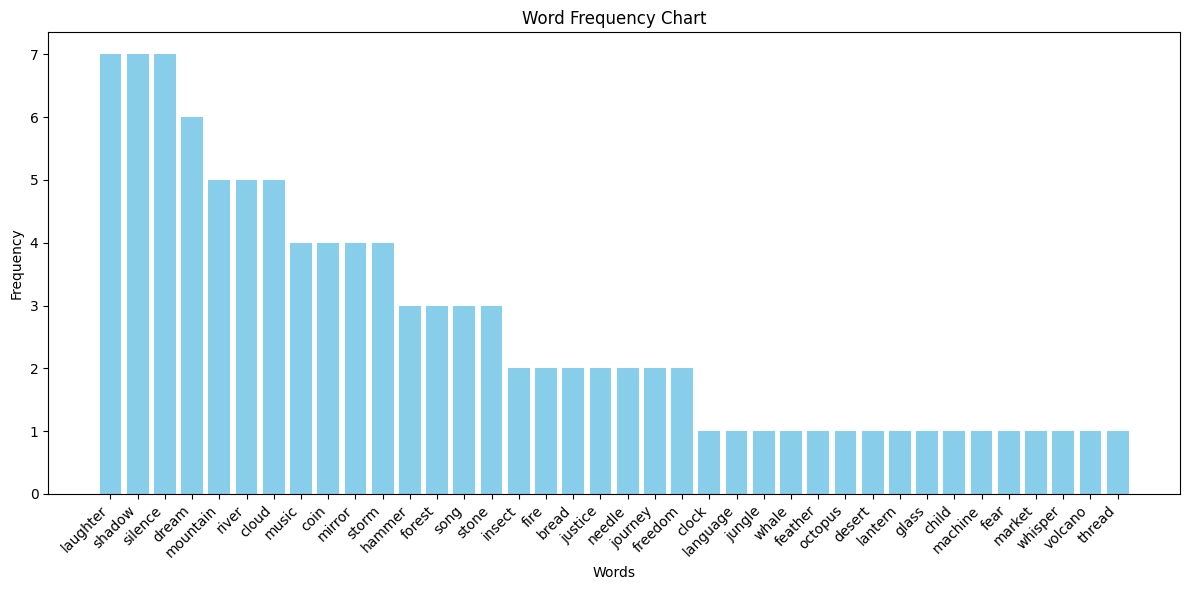
4. GPT-5 Thinking
GPT-5 Thinking achieved the highest diversity, generating 54 unique words across ten attempts. While it showed a marked preference for "justice" (appearing in 6 trials), this was the only word used in more than half the runs. Most impressively, the majority of words appeared in just a single trial.
Verdict: GPT-5 Thinking wins this one.
DAT scores
To score creativity objectively, the test measures "semantic distance" -- how closely related two words are. It measures this using the Common Crawl corpus, which contains billions of web pages, to reveal which words typically appear together. For instance "cat" and "dog" have a small distance (often paired), while "cat" and "book" have a larger distance (rarely paired).
In the DAT, the final score is the average of all word distances. Here’s how the models stacked up:
1. o3 mini
o3-mini produced tightly clustered scores between 65 and 72, with an average of 68.1 and a peak score of 71.8. This scoring pattern aligns with the repetitive word choices observed earlier.
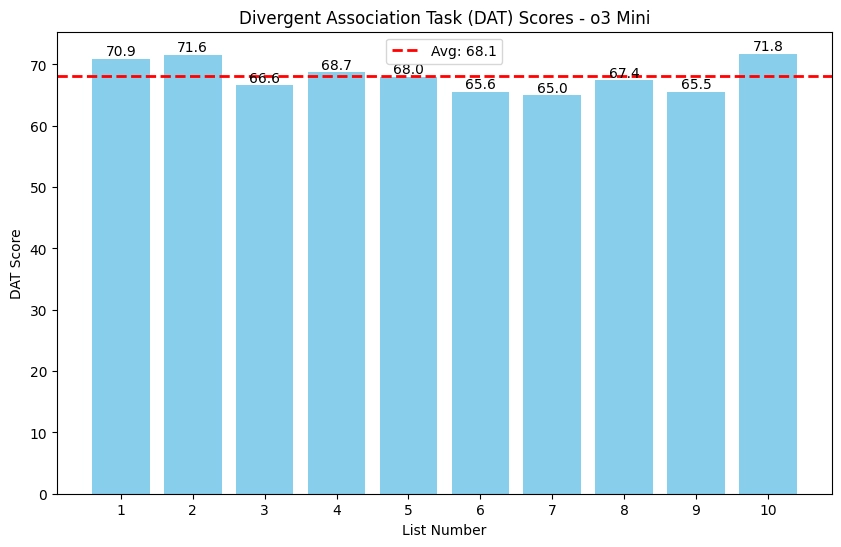
2. ChatGPT-4o
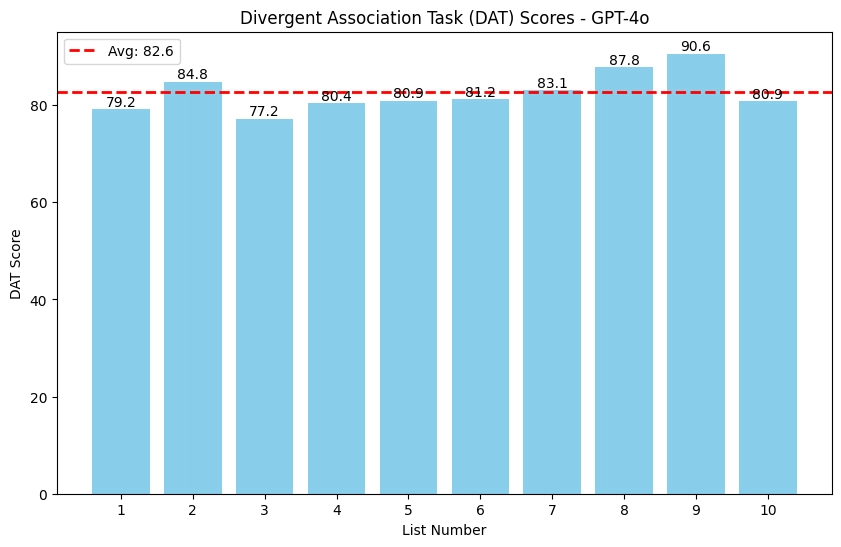
Meanwhile, GPT-4o's scores were a lot more variable, from 77.2 to 90.6. Its monster 90.6 score puts that run just above the top 25% of humans and well above the human average.
3. GPT-5 Fast
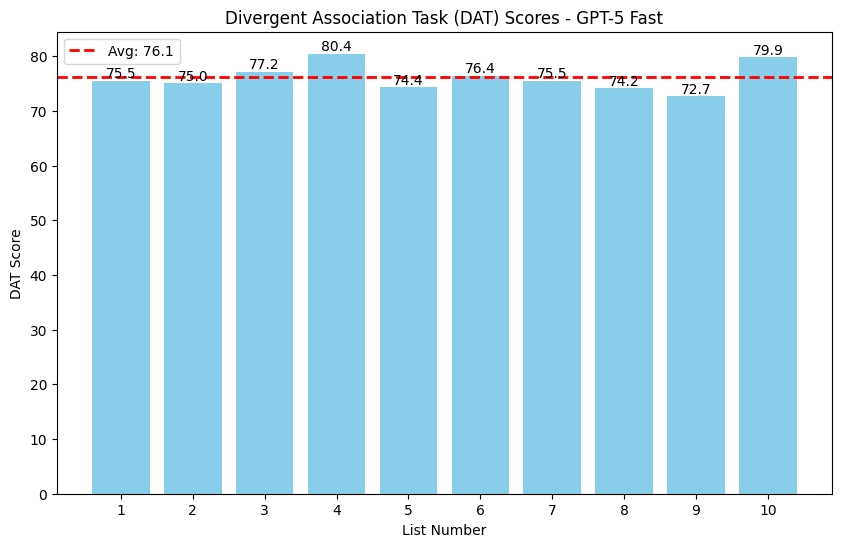
GPT-5 Fast had an average score of 76.1 with a high score of 80.4 across the ten runs, putting it below ChatGPT-4o.
4. GPT-5 Thinking
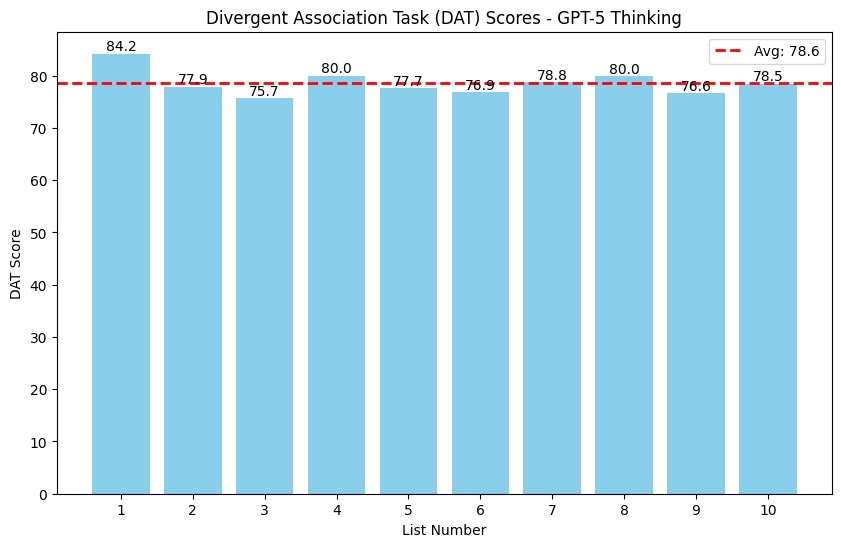
GPT-5 Thinking landed in the middle. Its lowest score (75.7) was higher than o3-mini’s best, but its top score (84.2) couldn’t touch 4o’s 90.6.
Overall: GPT-4o led the pack, followed by GPT-5 Thinking, then GPT-5 Fast, with o3-mini trailing.
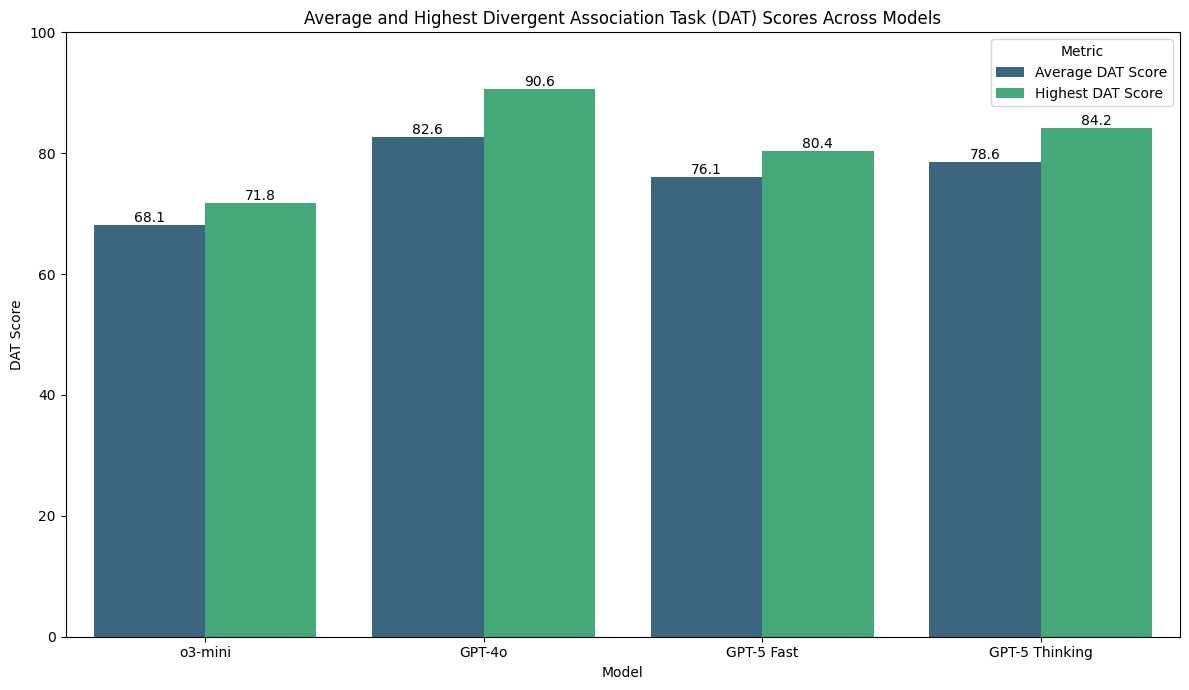
Interestingly, letting GPT-5 “think longer” did tend to nudge scores up a bit. But the fact that GPT-4o outperformed it without explicit reasoning suggests AI can actually overthink creativity in this task.
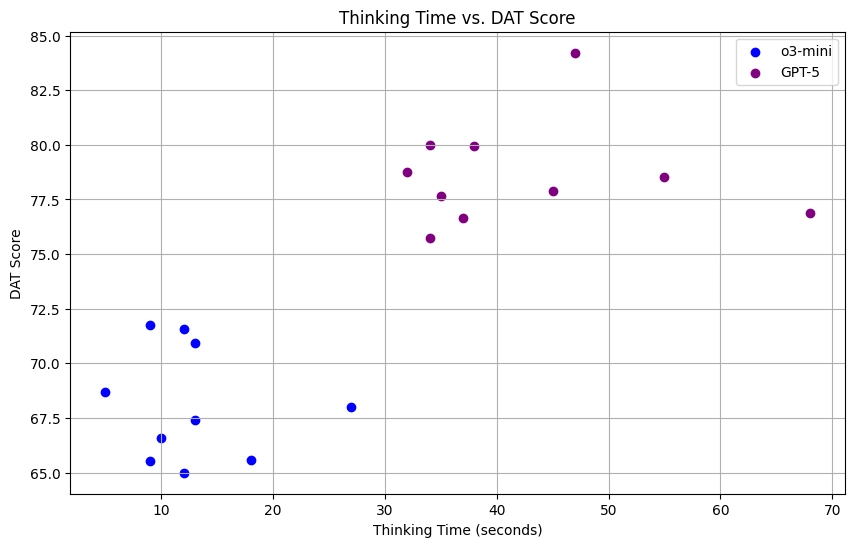
Verdict: This round goes to ChatGPT-4o.
Idea variety
AI brainstorming is huge for my workflow, so I needed to know: which model actually generates the best ideas?
For this, I challenged each model to generate 100 product ideas for college students. This is a testing approach that’s been used in recent research to measure brainstorming diversity.
For this exercise, both thinking models, o3-mini and GPT-5 Thinking followed the instructions and generated all ideas in one go, with GPT-5 making sure that it could complete the task within the context window.
ChatGPT 4o wasn't able to reason around its context window, so it generated 10, then 70, then the last 20. While this fragmented approach still produced the required 100 ideas, no surprise, it wasn't able to do any internal planning and resource management.
Measuring idea similarity
Each pair of generated ideas got a score from 0 to 1—the closer to 1, the more similar the ideas; the closer to 0, the more distinct the ideas.
For effective brainstorming, we want to see low similarity scores, which would mean that the model is exploring very different ideas rather than generating variations on a theme.
o3-mini performed the worst, with an average similarity score of 0.32. Its most similar pair was almost identical, scoring 0.91.
ChatGPT-4o delivered solid diversity with a pretty low average similarity score of 0.22. It consistently avoided generating highly similar ideas, with its most similar pair scoring 0.84.
GPT-5 Thinking achieved the lowest average similarity score of 0.21, just slightly under ChatGPT-4o. That means it had the most diverse idea generation overall. Most impressively, its most similar pair scored only 0.64, significantly lower than the other models' peaks, suggesting it actively avoided generating redundant concepts.
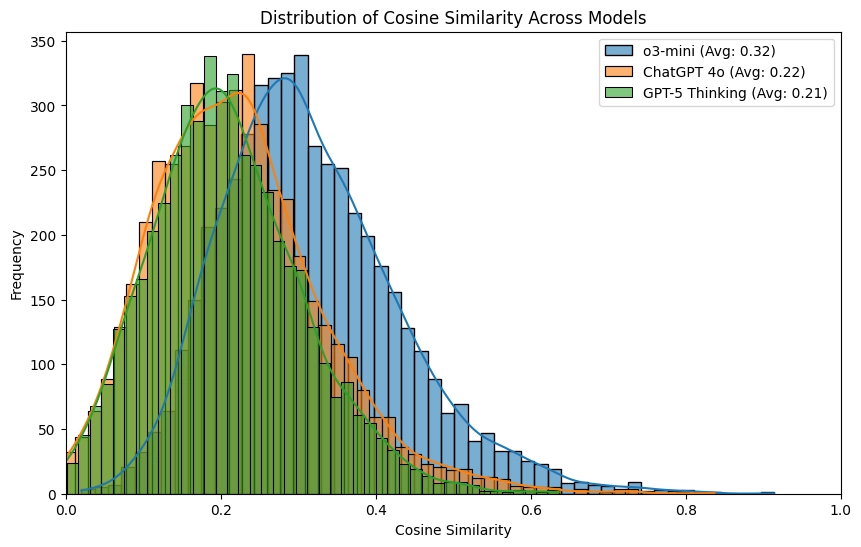
Verdict: This was a close one, but I'm giving it to GPT-5 Thinking because it had a much lower top score and because it followed the instructions in one go.