Imagine you've got 10 video clips all with filenames like "video_5300.mp4," and you need to find that perfect 10-second clip of someone biting an apple. Usually, that means rewatching everything and hoping your patience holds out.
Our engineering team at Descript had a different idea. What if our AI agent, Underlord, could actually see what's happening in your videos, not just hear what's being said? That way, you could just say “find a 10-second clip of someone biting an apple,” and boom—the clip would be right there, ready to work with.
That's the story behind media understanding, a new AI superpower that transforms how you work with visual content—because now Underlord can watch your video.
More than just better transcription
Giving an AI agent eyesight is not easy.
"In a video, you have a lot of different objects, characters, and interaction between them. So capturing that is a hard problem," says Ishaan Kumar, Descript’s AI research lead who spearheaded the project.
The challenge goes beyond just processing more data. "You might have a lamp sitting on a table,” Ishaan says.” To us, it's not important, but it might be important for someone who's going to use that later on in some edit." Since we don't know what’s important to a given user, we need to capture everything in the video in case the user wants to find it at some point.
This creates what software engineer Sylvie Lee calls "magical-feeling actions"—things like automatically splitting footage into scenes when someone claps their hands, or finding similar visual moments across all your project files.
The technical magic (it's simpler than you'd think)
The core concept is surprisingly straightforward. "Video is just a collection of frames, which are just images," Ishaan says. The team uses multimodal models—models that can deal in not just text, but images too. “They can take in images and then you can ask them questions about those images."
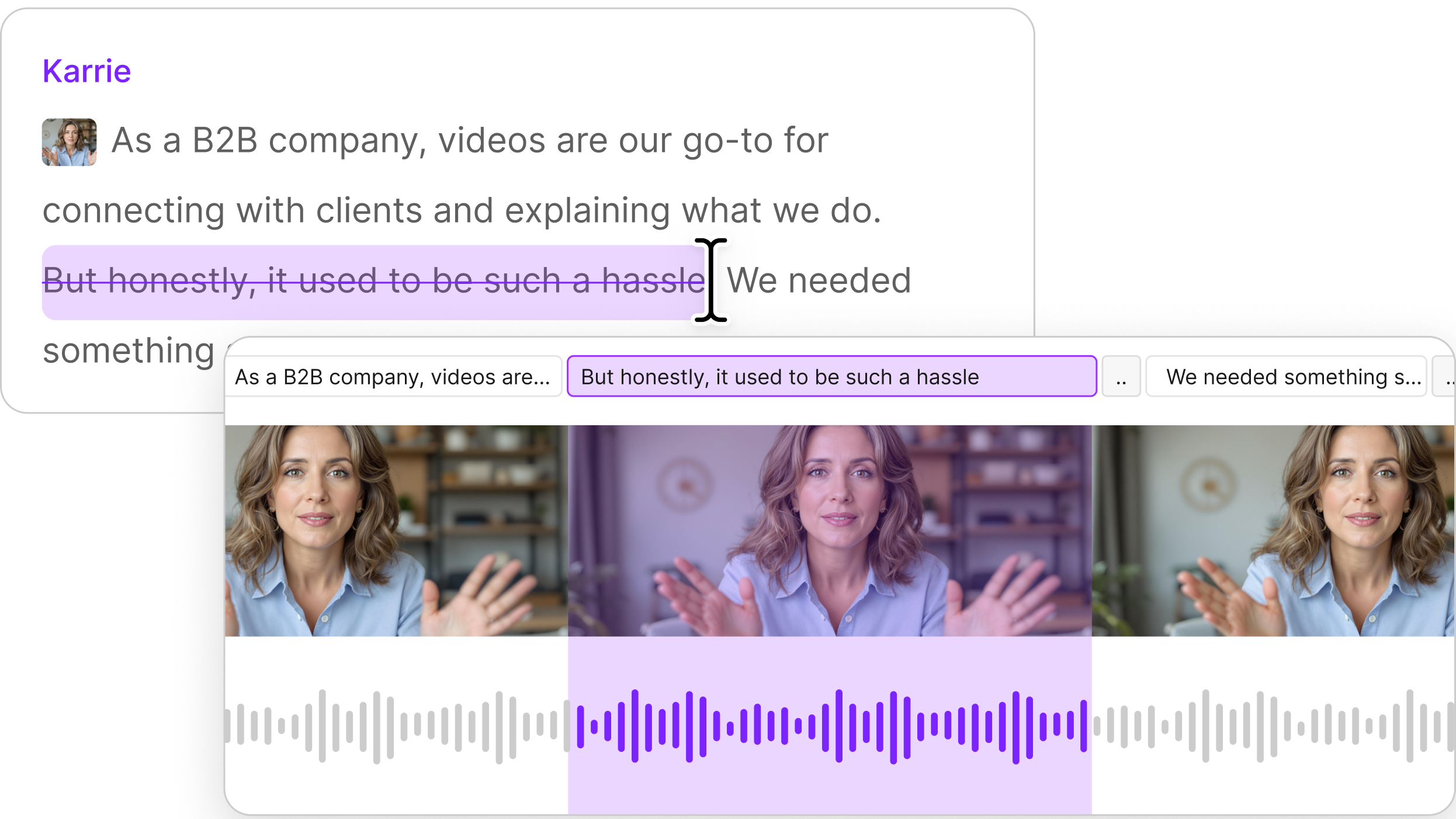
The team sends individual video frames to AI models, which then describe what they see. Software engineer Stephen Tsai put it in simple terms: "We send these images and then we stitch them together into like a big file, which you can literally just read,” he says.
Imagine a movie script that says “between second zero and second 15 a character is riding a dragon." Now you can ask your video editing agent to "find me a 15 second clip where a girl is riding a dragon" and get an answer in seconds instead of spending an hour scrubbing through footage.
The art of making AI predictable
One of the trickiest challenges was making the system feel reliable despite AI's inherently unpredictable nature. "It's like a bit more art sometimes than like pure science," Stephen says.
Their solution involves what they call "Top K" evaluation—essentially checking whether the correct answer appears in the system's top results, even if it's not the first choice. "If we look at the top hundred results and see if the model was able to retrieve the video that I was targeting, and if it's able to find that, we say it's doing a good job," Ishaan says.
They also built custom evaluation systems, to test the system’s accuracy, from scratch. "When we started this project, there was no public eval for the kind of task that we are doing," Ishaan says. The team created their own benchmarks with videos where they knew exactly what happened when, so they could easily test the system.
The economics of seeing
Cost optimization became a fascinating puzzle. The team discovered they could tune two main variables: the number of frames sent per video chunk and the resolution of those frames.
"Do you send all of the frames? Do you send the full resolution frames or not?" Ishaan says. "Sometimes it saturates—you're just sending tokens, burning money, and then you're not getting the expected return."
The tradeoffs can be surprisingly nuanced. Take someone writing on a chalkboard: "The model can actually look at the text and say that the teacher is teaching a physics lesson if you send it at 4K," Ishaan says. "But if you send at like 360p, the model is going to say someone is writing on the blackboard. That's it."
Different videos, different approaches
Not all videos are created equal, so the team built specialized handling for different content types. Screen recordings get higher resolution processing to capture text and mouse positions. Slide-based videos get full resolution treatment for OCR accuracy. Talking head videos get lighter processing since most information comes from the transcript anyway. They can trigger different workflows depending on the way the video is classified.
What this actually unlocks
The real magic happens when users start combining visual understanding with traditional editing workflows. Instead of just inserting generic stock footage, you can now tell the agent: "Look in my media and, based on my script, add the appropriate B-roll where it's intended to go," Sylvie says. The next level of personalization: create some bespoke B-roll using geneterative video (which Underlord can also do now).
But users quickly pushed beyond the team's initial expectations. "We had an idea that we want to just give people the ability to insert that five second clip of someone writing on a chalkboard," Stephen reflects. "We found that the things that people want to do are actually much bigger and wider than we anticipated."
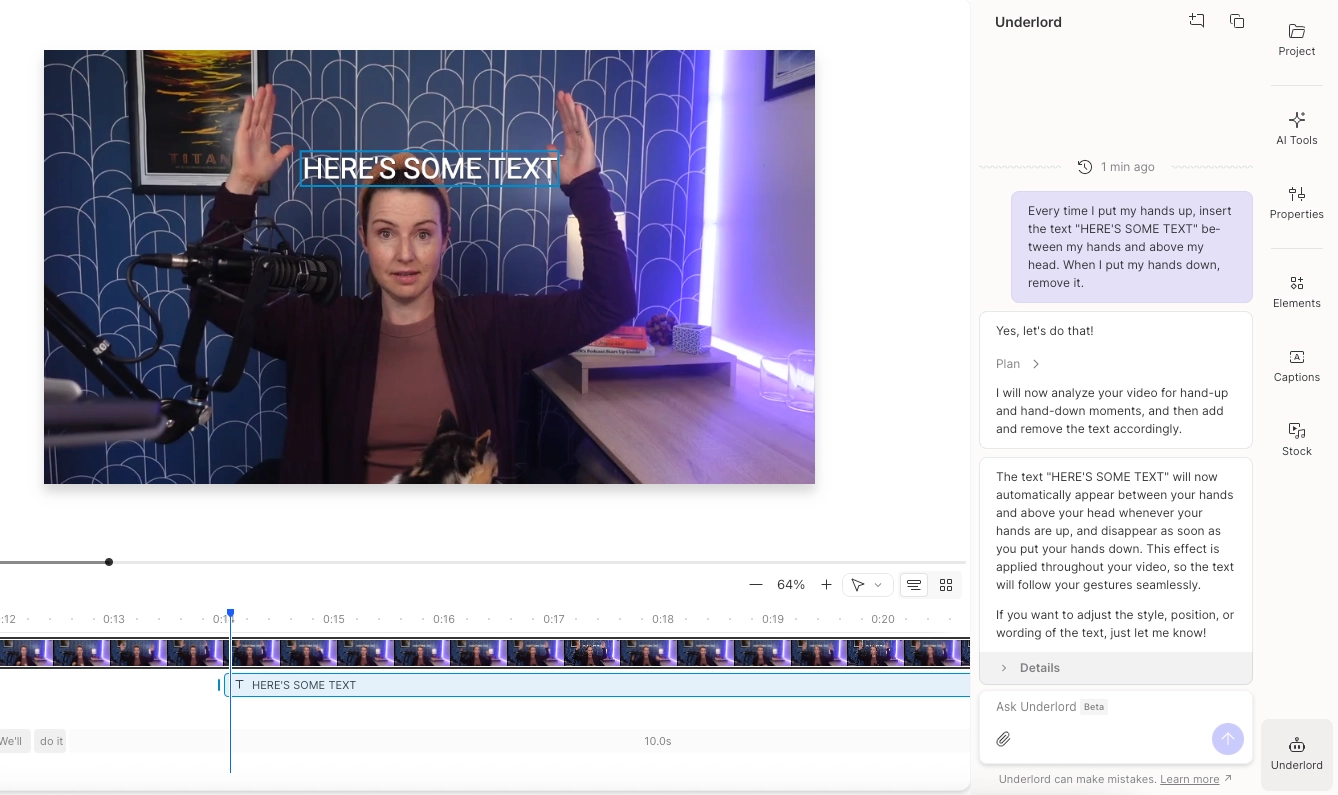
Some of the wilder requests? "Every time Martha sneezes, insert a GIF," or "stick text in here every time I raise my hands,” Stephen says as he raises his hands like he’s holding a beach ball. One user even uploaded a kid's baseball game and asked the system to automatically chop it into usable clips.
From idea to reality (surprisingly fast)
Maybe most impressive was the development speed. The team went from concept to working prototype in just a week and a half.
"Today's models are so easy to test," Ishaan says. "I had the first version working in like five minutes—you just go to any API provider and you just need a video file. You can say ‘describe this’ and it'll describe it."
Of course, turning it into a usable product feature is an entirely different matter.
What's next
This is just the beginning. The team is working on project-level search across all files, smarter layout recommendations based on video content, and deeper integration throughout the entire Descript platform.
"There's so many things that people are excited about," Stephen says. This is both an opportunity and a challenge. Sometimes the system surprises them by working with random queries they never expected. Sometimes it doesn't.
But as Sylvie puts it: "This is just the beginning of what we can do. It's only going to improve from here; get cheaper and more accessible."
The future of video editing is less about understanding complicated software and more about knowing what story you want to tell. With AI handling the grunt work of finding and organizing content, creators can finally focus on being directors instead of software operators.